

SKILup Day: SRE
The first SKILup Day of the year has concluded! SKILup Day: Site Reliability Engineering (SRE) was held on Thursday, February 17, 2022, with a brand new look and event platform. The one-day virtual conference explored SRE as a discipline. It featured “how-to” lessons and insight from speakers Jayne Groll, Dave Stanke, Tracy Ragan, Viktor Farcic, Marc Velasco, Yuri Grinshteyn, Manish Pande, Suresh Mathew, Lee Gilmore, Bill Manning, Colin Fallwell and an archive session on the History of SRE from Benjamin Treynor Sloss himself.
In addition to a full day of sessions, the event offered yoga, a scavenger hunt, session chats, sponsor hall and even a DevOps-inspired mixology class!
If you missed the SRE SKILup Day, never fear! We’ve got you covered with a quick round-up of the top themes that emerged from the sessions and conversations around this incredibly important topic.
Why Devote a Full Day of Learning to SRE?
Site Reliability Engineering (SRE) has gained the attention of IT and business technology individuals and leaders across enterprises, service providers and automation vendors. Introduced by Google, SRE leverages a software engineering approach to IT Operations and Infrastructure with the goal to modernize such.
To further emphasize its importance, 47% of 2021 Upskilling survey respondents voted SRE skills as a must-have skill in the process and framework skill domain compared to 28% in the previous year’s survey.
SKILup Day speakers covered several trending themes, including introducing various aspects of SRE, an in-depth look at managing the testing tool stack, testing challenges and requirements, and real-life use cases and experiences. Here are some of the key discussion points that emerged throughout the day.
Have a listen! The Humans of DevOps Podcast: Life of an SRE at Google with Ramón Medrano Llamas
Laying the SRE Foundation
A key theme among speakers at this SKILup Day was introducing the audience to various foundational aspects of SRE.
The event kicked off with an archive session on the History of SRE from Benjamin Treynor Sloss of Google – the Founder of SRE. Sloss provided a high-level overview of what an SRE is as well as who can be an SRE.
Dave Stanke of Google shared key insights during his session “DO, RE, Me: Measuring the Effectiveness of Site Reliability Engineering.” Stanke provided findings from the 2021 State of DevOps report about SRE, which found that SRE practices are widespread, with most teams surveyed employing these techniques to some extent. “SRE works: higher adoption of SRE practices predicts better results across the range of DevOps success metrics,” said Stanke. He then explored the relationship between DevOps and SRE and how even elite software delivery teams can benefit through the continuous modernization of technical operations.
Improving SRE Practices
Various sessions also detailed how to improve your SRE practices.
During her session, Tracy Ragan of DeployHub took on Chaos Engineering during her, “Chaos Engineering – Are We Brave Enough?.” Ragan explored basic concepts of chaos engineering – a site reliability practice of breaking production on purpose. Ragan said, “That sounds like a crazy radical idea. But to be honest, it might be the best way to guarantee your system’s resilience.” Ragan then provided specific insights into the cultural shift required to implement a chaos engineering practice so one can decide if it is something they want to champion at their organization.
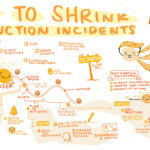
In the session, “How to Shrink Production Incidents,” Yuri Grinshteyn of Google Cloud detailed an approach that SREs can use to reduce the overall impact of production outages. Grinshteyn shared how to prioritize reliability-related engineering tasks based on incident postmortem data. He then explored how to reduce time to detect incidents, how to shorten the time to repair and expand the time between failures.
Suresh Mathew of Sedai and Lee Gilmore of AO teamed up for the session, “Fireside Chat: Why Automated Solutions Aren’t Enough When It Comes to Managing Your Cloud.” They emphasized that while the shift from monolith to microservices “changed the game” regarding deployments and team velocity, it simultaneously introduced the monotony of daily repetitive work and manual tasks. They then explained that SREs and DevOps now need to rethink how teams manage their applications on a day-to-day basis. Further, they stressed that while a highly automated approach can certainly help with application management, these systems are not independently intelligent. They then explored how to evolve an automated system into an autonomous system, how FAANG and PANDA companies build autonomous systems and the new role of SREs in an autonomous world.
Looking for more SRE inspiration?: Read From Pilot to Scale: The Successful SRE Journey at a Large Financial Institution
Enabling the SRE Team
Enabling SREs to build reliable applications was another common theme that emerged. Many speakers had specific insights into how to prepare your SRE teams better.
Manish Pande of Infosys shared key insights during his session “Stretching the Discipline of SRE Upstream Towards IT Development.” Pande reviewed the role development teams can play in developing and delivering reliable systems. He then explored the set of practices that they can adopt through the development lifecycle and collaborate effectively with SREs to deliver a reliable system. As a result, developers spend less time in escalations in production and focus on their core objective of faster development and innovation.
Viktor Farcic of Unbound returned to SKILup Day with his session “Why You Must Apply Automated Drift Detection.” In his session, Farcic indicated that “no matter what happens to our resources, Kubernetes will always try to converge the actual into the desired state without human intervention.” Further, he shared the effects of having (and not having) automated drift detection and reconciliation applied on infrastructure. He then explored Crossplane as one possible solution that enables SREs to leverage Kubernetes API to manage infrastructure and services.
In the session, “Demystifying SLIs/SLOs/SLAs,” Marc Velasco of IBM highlighted the differences/uses of SLIs/SLOs/SLAs, where they are used and in what capacity. He said, “As Site Reliability Engineers (SREs), our job is to engineer reliability for a service. SREs do this using data to drive decisions.” Velasco clearly explained SLIs/SLOs/SLAs and how they are used in SRE activities. Aside from the basic definitions, he shared best practices and the different ways these derived metrics can be used together to deliver reliable, resilient services at rapid velocity.
Supply Chain Management/Shift Left
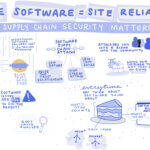
Bill Manning of Jfrog shared practical advice and tips during his session, “Secure Software = Site Reliability: Software Supply Chain Security Matters.” Manning emphasized that “Ensuring that your company has the most reliability doesn’t start with the deployment but with the development of the hosted software. The applications you are running are susceptible to everything from security issues with third-party libraries that make up 85-90% of the software you host and misconfigurations and other threats to its reliability.” His session covered the importance of Software Supply Chain Management, accountability of your developers and build systems, and why better software means improved reliability.
Finally, Colin Fallwell of Sumo Logic shared firsthand experience during the session “Observability Driven by Design.” Fallwell indicated that “building modern applications that provide flexibility and portability can present monitoring challenges if developers don’t adopt an instrumentation first approach.” He then shared how to shift observability practices left and empower developers to think about observability earlier in the SDLC.
Graphic Summaries
Want to know more about the sessions? For a quick recap of each, check out the sketches below.





Get DevOps Certified
Today’s organizations deal with a higher volume of change in a more complex tech environment leading to a higher risk of outages and incidents. IT teams must improve service reliability and system resiliency. With automation and observability becoming key factors for more efficient and rapid deployments, the SRE profile has become one of the fastest-growing job roles.
DevOps Institute offers both SRE Foundation and SRE Practitioner Certifications. Learn more and get certified: https://www.devopsinstitute.com/certifications/
Access even more SRE resources by becoming a member of DevOps Institute today.


![[EP112] Why an AIOps Certification is Something You Should Think About](https://www.devopsinstitute.com/wp-content/uploads/2022/01/DOI-Human-DevOps-Digital-Podcast-Screen-600x600px-400x250.jpg)