
By: Orit Golowinski
Progressive delivery is the process of pushing changes to a product iteratively, first to a small audience and then to increasingly larger audiences to maintain quality control. Progressive Delivery is a modified version of Continuous Delivery, so let’s start from the beginning.
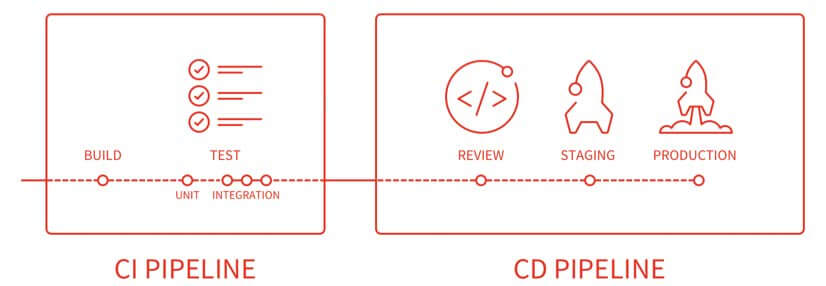
Continuous Delivery is a software development discipline where you build software in such a way that the software can be released to production at any time. You achieve continuous delivery by continuously integrating the software done by the development team, building executables, and running automated tests on those executables to detect problems. Furthermore, you push the executables into increasingly production-like environments to ensure the software will work in production.
Let’s expose some of the methods of progressive delivery.
Review Apps
Review apps provide an automatic live preview of changes made in a feature branch by spinning up a dynamic environment for your merge requests. This environment is automatically deleted when the branch is deleted. This creates a new app for every topic branch, automatically and allows you to test and demo new features without having to deploy to dev or staging in order to preview your changes. This increases team collaboration and lets anyone check out exactly what a merge request is going to look like without having to download and run a topic branch. QA and other users can take a look without having a development environment installed on their laptop at all by simply clicking on a URL.
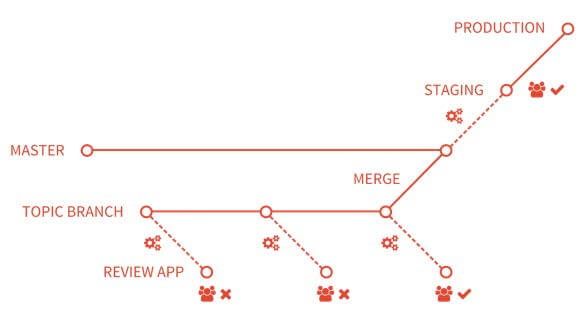
Review apps are extremely powerful and offer a production-like look and feel to the feature in development, but production-like is not quite production. In order to be confident on how something will behave in production, you need to actually test it in production. Testing in production seems quite scary to people, but it doesn’t have to be. Let’s discuss how we can test in production while minimizing risk.

Blue/Green Deployments
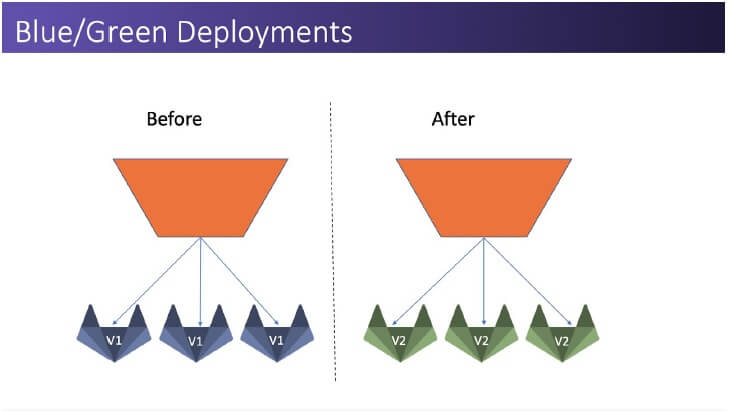
You deploy to two environments, while “blue” is exposed as production to users. Development continues on the “Green” environment and once you are ready to swap – all the user traffic is routed to the “new production” environment which is “green” and now development continues on “blue” The biggest downside for this is that if something goes wrong – all the development is rolled back and not just the faulty feature.
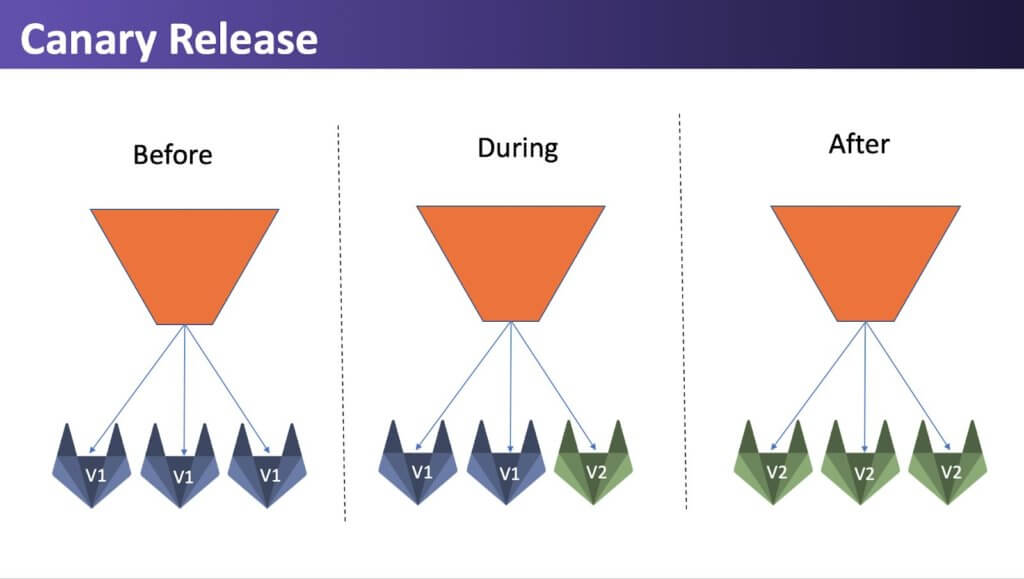
Canary Releases
In a Canary Release, you start with all your machines/dockers/pods at 100% of the current deployment. Now you are ready to try out your new deployment on a subset of your users, let’s say 2%. So, in this example if there are 100 machines, two of the servers will get the new deployment, sending 2% of your population there. You will need some logic somewhere to figure out how to route those users and you’ll need to decide whether the user routing decision needs to be sticky (it probably does).
Now you want to pay close attention to how those servers are doing and whether there are errors/performance degradations etc. for this gives us immediate feedback on our new׳ behavior, and allows us to continue deploying additional servers, until we reach 100%.
If anything goes wrong, you just drain the traffic from whatever is sending the traffic to those canaries and route back to production. Then you are back to the way you were at 100 percent production. Similar to blue/green – rollback is for the entire development so all the features are rolled back again and not only the faulty feature.
Feature Flags
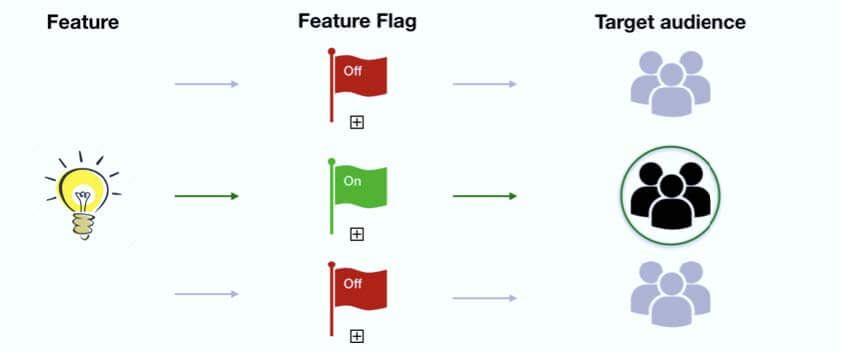
Feature Flags can be used as part of software development to enable a feature to be tested even before it is completed and ready for release. A feature flag is used to hide, enable or disable the feature during run time. The unfinished features are hidden (toggled) so they do not appear in the user interface. This allows many small incremental versions of software to be delivered without the cost of constant branching and merging.
Feature Flagging is basically Canary for features. Allowing you to roll out features gradually, slowly exposing features. If something goes wrong, you can confine the feature to a smaller audience or even to different environments. The feature still lives in production, but is not available.
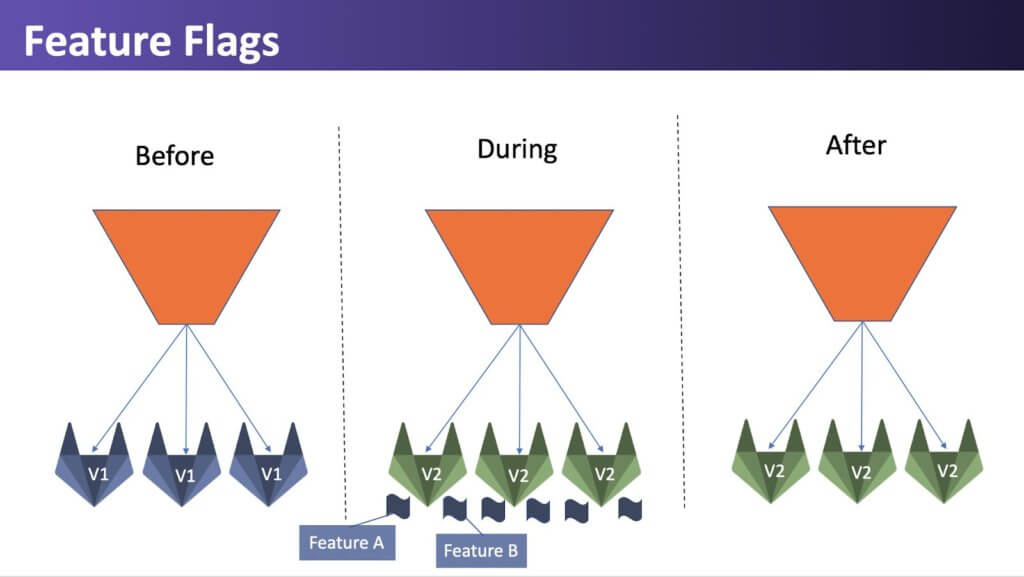
Feature flags work like an if/else inside your code, some users will match the first criteria (old deployment without the new feature) while another percentage of users will reach the else statement and will be able to use the new feature. As in canary, this allows you to get immediate feedback for the new functionality, and once you gain confidence, you can increase the percentage of users exposed to the new feature until you hit 100%. A really nice benefit that is gained from using feature flags is that the rules for the condition can change on the fly at any time.
A specific use case for feature flags is percent rollout, in the example below, you can see that the rollout starts at 10% and slowly increases until 100%.

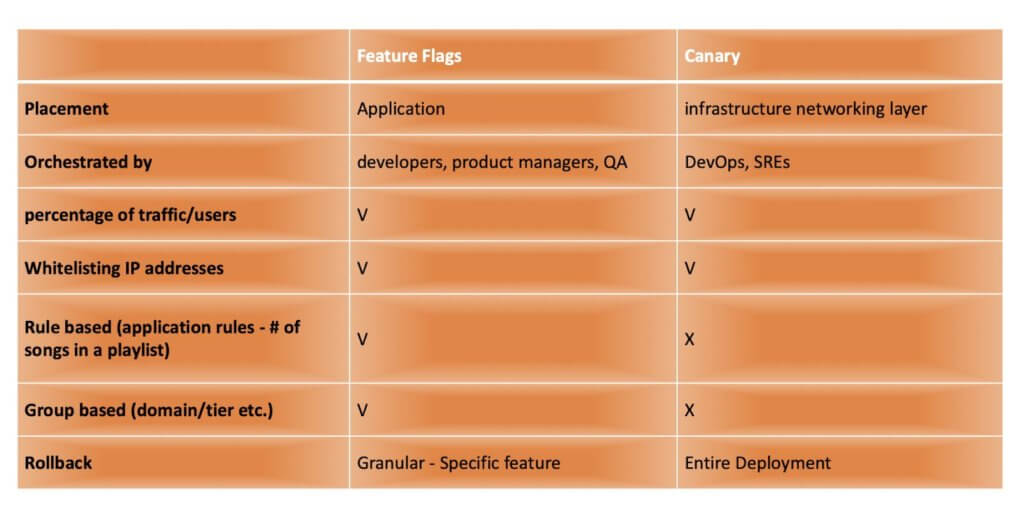
Feature Flags vs. Canary Comparison
Feature Flags and Canary releases are similar in concept. The table below highlights some of the similarities and differences between the two methods.
Combining Feature Flags with Canary
Combining feature flags with canary allows you to get the best of both worlds. You can deploy canary releases with all of the feature flags turned off and monitor the canary.
Once you are confident that the canary is stable, you can slowly turn on and monitor each feature flag individually to see if you can increase the exposure. Turning off a feature flag does not require rolling back the entire canary deployment so even if it needs to be turned off, the rest of the features can still roll out to production.
A/B Testing
A/B Testing can be thought about as an extension of feature flags. A/B testing allows the testing of variables on different groups of data and monitoring which is the preferred method. Take for example a website that wants to increase sales and want to check which workflow will result in users adding more items to their cart. Developers can experiment with different user flows each one sending the user through different routes in the Websites UI. The developers monitor the website for some time and see which flow resulted in the most revenue, and this will be the chosen workflow for all users once the experiment is done. This is efficient to test the change in usability, based on the test results, which can be business goals, better performance, customer engagement and more.

Progressive Delivery Pros and Cons
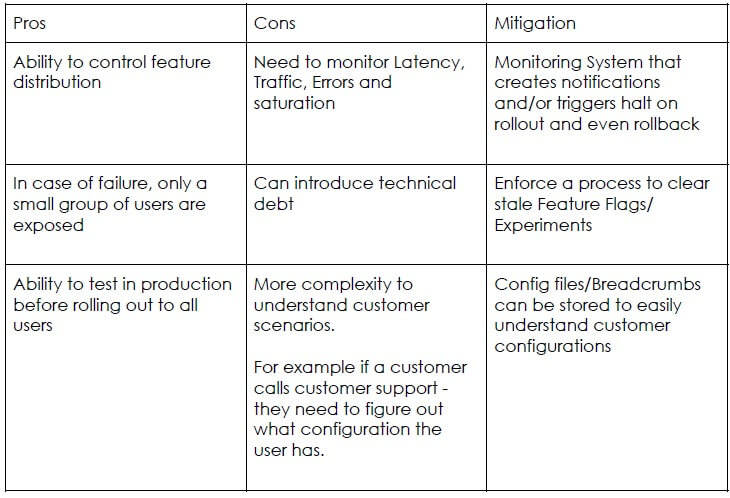
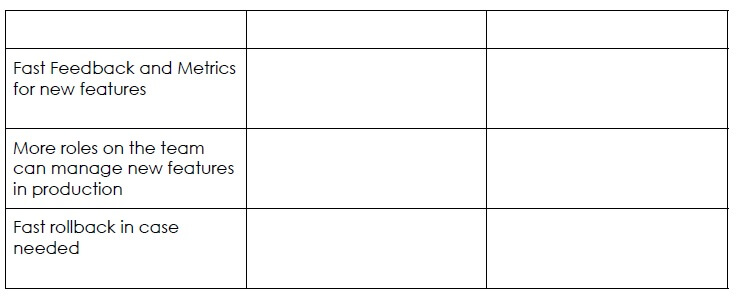
Conclusion
When you want to test in production, it is important to monitor the system and have an easy way to rollback. The different factors of progressive delivery are environments and users. When controlling environments, developers can deliver features progressively into environments to limit exposure when new code is deployed. When done for users, users are segmented in some way- can be arbitrarily by percentage, or by a specific identifier such as domain (for dogfooding), the developer progressively delivers the changes exposed to that set of users. It is all about the feedback loop and making a conscious decision whether you can continue roll out or if you need to rollback. When we think about this change in the state of mind, even the ownership of features in production changes. Originally features were owner by the engineering team, now once the features hit production, ownership moves to release managers, product managers and customer support teams, who are closer to feedback from the customers and this frees up more time for developers to work on newer development.
This article is adapted from a talk that I gave at DevOps Institute’s Continuous Delivery SKILup Day.


![[EP112] Why an AIOps Certification is Something You Should Think About](https://www.devopsinstitute.com/wp-content/uploads/2022/01/DOI-Human-DevOps-Digital-Podcast-Screen-600x600px-400x250.jpg)