
Updated January 18, 2023
By: Anurag Sharma
In an increasingly distributed world, we often ask ourselves if continuous delivery can accommodate legacy software systems and if we can use chaos engineering to improve reliability in these environments. There is an assumption that legacy can’t be agile, or an attitude that its future is uncertain but sure to be short. But nobody knows how short, and it could be years or even decades before this type of technical debt can be worked away. Legacy is heritage, is cherished and often represents core business systems in an organization; cash cows that the business depends on, that have become highly complex during their existence and as such are incredibly difficult to replace and cannot just be abandoned.
Can Chaos Engineering Help with Legacy Systems?
Not everyone is a unicorn, born on the web FANG. These organizations carry some legacy. Legacy applications carry with them legacy databases built on technologies, and there’s a good chance most organizations have to deal with massive old-style RDMS. Whilst a vast majority of global IT teams are moving from monoliths to microservices, there is always a transition period where legacy applications and components need to operate close to the speed of the new world. These legacy monoliths typically have a tightly coupled architecture that needs to be loosened to allow for incremental, small-batch change, test, and release in order to enhance velocity.
There is a proven approach for building consistency into software development, Continuous Delivery, which is here to stay. On the IT operations side, we have chaos engineering, capable of swiftly uncovering the failures of software that teams aren’t aware exist but have the potential to ruin a business. Chaos engineering carries a real and very clear message that it’s preferable to constantly practice small failures than increase the risk of catastrophic public failure, which can seriously and adversely impact a business’s reputation.
The idea is to consider the overall ecosystem and when it comes to legacy, choose your battle appropriately, which includes all your critical legacy systems.
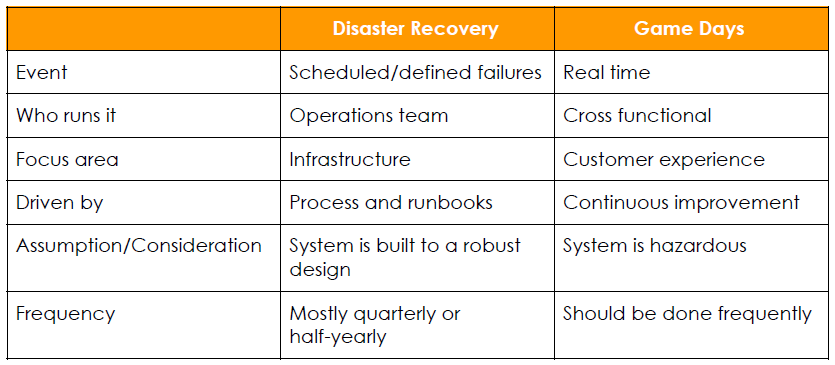
Let’s clarify before we go further. There are differences between resilience assessment approaches, Disaster Recovery versus Game Days.
What doesn’t matter for Chaos Engineering:
- Size of your organization and team
- Language technologies, development methodology (Waterfall/Agile)
Why You Should Bring Chaos to Your Legacy CI/CD Pipelines
The ultimate goal of your CI/CD is to automate the software build process to enhance velocity. Once you set it up, it makes sense to integrate chaos engineering with your CI/CD. As part of the deployment pipelines, you can push your chaos files to start disruption in the specific environment. Here are a few scenarios:
- Make legacy dependencies unavailable when you push a deployment
- Introduce a failure in key codes and orchestrate a canary deployment
- Reduce the capacity and run the load test just after deployment
Useful Experiments on Your Build cycle
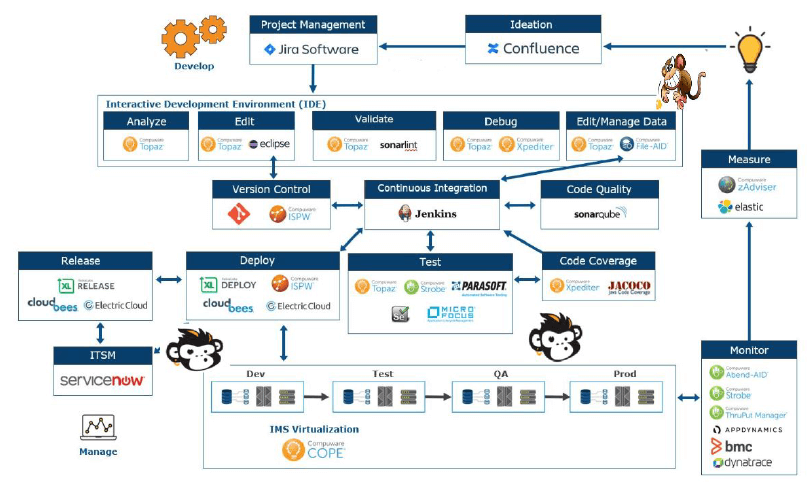
Here are some examples:
For legacy pipelines, let’s take the example of the mainframe. It starts with version control tools like ISPW, ChangeMAN, etc, Build, Release, Deploy e.g. Topaz, IBM tools, etc, Operate manual/automated, Monitoring BMC, Splunk, etc. Here are two chaos experiments that help to assess your pipeline:
- Application-specific experiment: Where a specific idea or test design should be applied to check the reliability, and this can be a one-off experiment. This can be used during development, building, testing, deploying, operating and monitoring
- GameDays: This will be more real-time with shared responsibilities across the team with a specific focus
The idea here is to speed up deployment and find issues before they hit production
What are the best monkeys for Game Days?
- Latency Monkey: Remember when you move away from legacy, you mostly remain in a transition state so it’s extremely crucial to ensure integration. You need someone to challenge your latency
- Big Iron King Kong (Legacy Monkey): This monkey should be able to allow you to experience below
- Key DB start/Stop automatically
- In introducing highly localized failure in a legacy system or make the system slow
- Terminate the entire database or disconnect from datacenter
For build pipelines, the golden spot remains in the middle because, usually, the software itself plays a role in responding to the failure. For example, the software might include an automated restart, throttling, failover, etc. If those are software functions, then the software can either work or not work, and the build should be able to uncover that.
A true differentiation of the best from the rest is, your growing focus on the reliability of the entire ecosystem, and how effectively you test the resilience of your system from build to all the way through production. Chaos Engineering along with the future of releases CD are two best set-ups that use it effectively and get the maximum value of it.


![[EP112] Why an AIOps Certification is Something You Should Think About](https://www.devopsinstitute.com/wp-content/uploads/2022/01/DOI-Human-DevOps-Digital-Podcast-Screen-600x600px-400x250.jpg)