

A SKILup Day: SRE Event Recap
On May 20, 2021, the virtual conference explored Site Reliability Engineering (SRE) as a discipline. SKILup Day featured “how-to” lessons from speakers Ryan Doherty, Mikolaj Pawlikowski, Shlomo Bielak, Sven Rupper, Dongfang Xu, Adam Clifford, Leonid Belkind, Marcel Birkner, Ravi Lachhman, Dinesh Sekar, Jason Yee, Chris Harding, Murdo MacLeod, Shivagami Gugan, and Santanoo Bhattacharjee.
If you missed the SRE SKILup Day, we’ve got you covered with a quick round-up of the top themes that emerged from the sessions and conversations around the importance of the topic.
Why Devote a Full Day of Learning to SRE?
SRE is a discipline that incorporates aspects of software engineering and applies them to infrastructure and operations problems. The main goals are to create scalable and highly reliable software systems. This SKILup Day offered an in-depth look at these trending topics from some of the top thought leaders in the industry.
SKILup Day speakers covered several trending themes, including introducing various aspects of SRE, an in-depth look at managing the testing tool stack, testing challenges and requirements, and real-life use cases and experiences. Below we look at key quotes and discussion points from the day.
Have a listen! The Humans of DevOps Podcast: Life of an SRE at Google with Ramón Medrano Llamas.
Understanding SRE
A key theme among speakers at SKILup Day was introducing the audience to various aspects of SRE, including culture as a key element. Many speakers had specific insights into common pitfalls and provided insight on how to avoid them.
Keynote speaker Ryan Doherty, Staff SRE at LinkedIn, kicked off the sessions for the day. He shared unique insights during his session, “10 Years of Failure: How Racing Cars and SRE Deal With Complex Problems.” The session featured insights from Doherty on what building a race car and winning races have in common when building information systems: “The systems we build today are no longer complicated, they are *complex*…” He also noted that “it takes a completely new paradigm for how we plan, build, and maintain these systems.”
Doherty also shared 5 key tips for handling complex systems:
- Go beyond root cause.
- Stop using ‘human error’.
- Search for systemic issues.
- Understand the boundaries and pressures involved.
- Understand that people create safety.
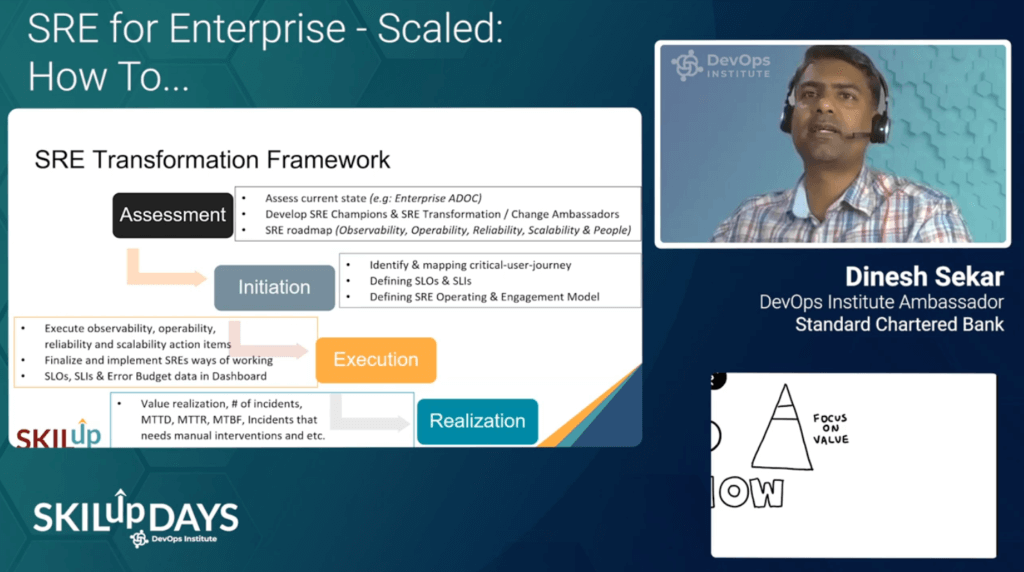
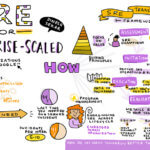
DevOps Institute Ambassador, Dinesh Sekar, returned for his second SRE SKILup Day with his session, “SRE Adoption for Enterprise – How to.” Sekar stressed that many organizations are not Google. He then went on to discuss how to adopt SRE at an enterprise-scaled organization. He gave tangible advice to those looking to overcome common challenges during an SRE transformation.
Sekar stressed the importance of empowering teams and embedding SRE across the organization’s culture. He concluded with the parting words, “As an SRE, how do we make tomorrow better than today?”
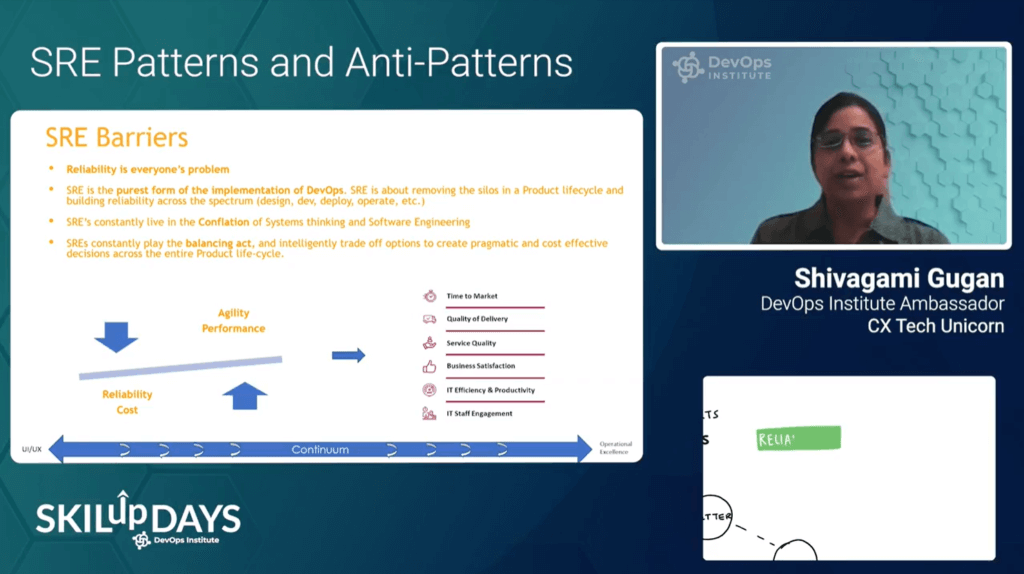
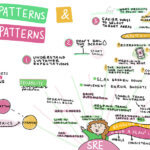
Shivagami Gugan, DevOps Institute Ambassador and Technologist and Aviation Specialist presented the session, “SRE Patterns and Anti-patterns.” During her session, she noted that “at any maturity level, there is always room for improvement at an organization for better business outcomes.” To concur with one of Ryan Doherty’s tips, Shivagami shared one of her favorite quotes from Jennifer Petoff, Director, Site Reliability Engineering Education at Google, when discussing SRE anti-patterns, “It’s never a human error, it’s a system problem.”
She shared many more anti-patterns such as point fixing, rebranding Ops, and the configuration management trap. She gave tangible advice for those looking to overcome common pitfalls along the path toward a successful SRE program including:
- Understand customer expectations.
- Don’t boil the ocean. (Select target areas and then scale)
- There are easier ways to select target areas.

What Is Site Reliability Engineering [and What It Is NOT]
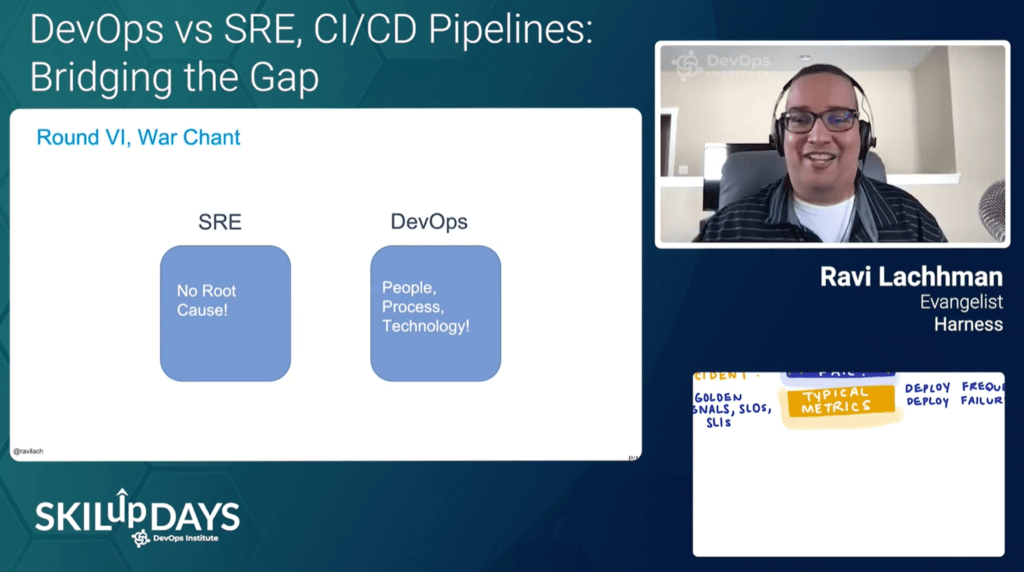
Understanding how SRE fits into other disciplines was another area of focus that emerged during SKILup Day. During his session, “DevOps vs SRE, CI/CD Pipelines Bridging the Gap,” Ravi Lachhman of Harness focused on the conduit between the two teams – a CI/CD pipeline. He also explored the different roles and responsibilities of each and how your CI/CD pipelines can be used in both times of joy and incidents.
He then emphasized that “Just because something is efficient doesn’t mean it’s resilient and because something is resilient doesn’t mean it’s efficient.” After a breakdown of concrete examples of how DevOps vs. SRE respond to situations, a key takeaway was that “reliability is everyone’s responsibility.”
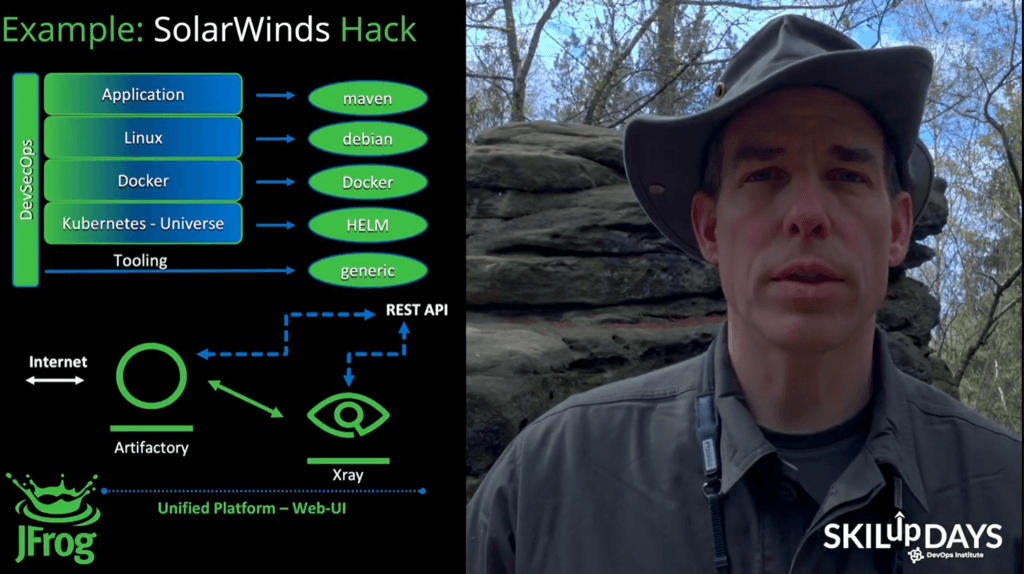
Sven Ruppert of JFrog delivered an impressive session, outdoors, in the forests of Germany: “How SRE fits into the DevSecOps World?” Ruppert explored how SRE and DevSecOps differ, and what each one means. He also shared insight on how security can be established in such a constellation.
Chaos Engineering and the Destruction Stage
Many speakers had specific insights into how Chaos Engineering and destruction can be utilized in SRE.
Keynote, Mikołaj Pawlikowski, Engineering Lead at Bloomberg, gave first-hand advice during his session, “Supercharge your SRE teams with Chaos Engineering.” The session included several of his personal learning experiences and insights to help and inspire SKILup Day attendees. He described Chaos Engineering as, “one of the most powerful tools at your teams’ disposal.” He noted: “Through experimenting and introducing failures, you can proactively find issues before they find you.”
Pawlikowski also presented Chaos Engineering myths and common barriers to adoption: “50 percent of respondents said generating buy-in was the biggest blocker for adopting Chaos Engineering.” He then shared strategies to convince your team to give the methodology a try including, “Getting fewer calls at night, day, or holidays while on-call using Chaos Engineering.”
Jason Yee of Gremlin also took on Chaos Engineering during SRE SKILup Day. He shared important findings from the first State of Chaos Engineering Report during his session, “Chaos Engineering by the numbers.” The first State of Chaos Engineering report is a survey of hundreds of organizations about how they’re practicing Chaos Engineering and the results they’re seeing. With concrete data from the report, Yee shared a few outcomes teams can expect from implementing Chaos Engineering:
- Increased availability.
- Reduced mean time to resolution (MTTR).
- Reduced mean time to detection (MTTD).
Yee also shared a few key points on adopting Chaos Engineering:
- There’s a process. It’s planned, not random.
- Validate your mental models/understanding.
- Use your knowledge to improve systems.
- Build practice and culture of learning.
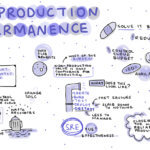
According to DevOps Institute Ambassador Shlomo Bielak, “The best way to remove brittleness is to change the Software Development Life Cycle (SDLC) to involve a stage of destruction.” During his session, “Non-Production Impermanence,” he presented the idea that to reflect true resilience and remove brittleness of applications and platforms together, you must change the SDLC by adding a new state to non-production ‒ destruction.



Enabling your SRE Team to Build Reliable Applications
Many speakers had specific insights into how to better prepare your SRE teams. During his session, “Using Statistical Inference for Capacity Planning,” Dongfang Xu of Splunk explored how to do smarter capacity planning using the linear regression functionality available in Splunk Infrastructure Monitoring. According to Xu, capacity planning helps to avoid possible stability and reliability issues, elevates performance by identifying bottlenecks, is a better cost model, and supports the service-level agreement (SLA) that you want to achieve.
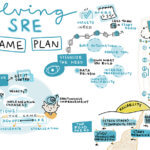
DevOps Institute Ambassador Santanoo Bhattacharjee presented the session, “Evolving with SRE – The Game Plan.” During his session, he noted that “while any transformation is driven by innovation, the end objective always remains reliability.” He also stressed that, “the core denominator of any growth equation is always discovering the elements of sustaining resiliency and reliability.” He proposed that a key question should always be clear, “We train & prepare ourselves for years just to be ready to fight something which has the power to lead to chaos in minutes.” The key lies in, “how much ready will we ever be!” He concluded with these parting words: “Do not emulate Google, they have a completely different structural case of having SRE in the first place. You will need to build reliability engineering constructs to refine your needs!”
During his session, “Using Automation for Generic Mitigations in Production,” Leonid Belkind of StackPulse gave tangible advice to help SREs, DevOps and Software Engineers in charge of production service environments be ready for various unexpected events and to maintain their service level objectives (SLOs). He stressed that “well-defined, pre-rehearsed and deterministic processes are a must to ensure efficient handling of incidents.”
Finally, Chris Harding of Epsagon explained the importance of observability in SRE during his session, “Observability and the Golden Signals for SRE in Microservices.” He stressed that “it becomes very difficult when you have this large amount of services to have true observability into what’s going on.” He presented that “distributed tracking is the last piece of the puzzle” and showed how you can leverage distributed tracing and microservices to achieve true observability within these complex architectures.



Site Reliability Engineering SKILup Day: Visual Summaries
Want to know more about the sessions? For a quick recap of each, check out the sketches below.

What’s Next?
Now more than ever, organizations need DevOps professionals with validated skills and knowledge to support their digital transformation. At DevOps Institute, we offer certifications across several core DevOps competencies to help advance your DevOps career and grow professionally.
Explore our SRE Certifications today.


![[EP112] Why an AIOps Certification is Something You Should Think About](https://www.devopsinstitute.com/wp-content/uploads/2022/01/DOI-Human-DevOps-Digital-Podcast-Screen-600x600px-400x250.jpg)